/
Blog · BaseTech
Toate articolele
Insights despre ERP, AI/RAG, agenți autonomi, pSEO, SaaS și data pipelines — scrise pentru companii care construiesc.
Insights despre ERP, AI/RAG, agenți autonomi, pSEO, SaaS și data pipelines — scrise pentru companii care construiesc.
Un sistem RAG rar costă cât crezi — și aproape niciodată din cauza LLM-ului. Împărțim factura pe componente, cu cifre concrete pe 2026.


Întrebarea „cât costă un sistem RAG" are un răspuns onest: depinde. Dar depinde de lucruri pe care le poți estima destul de precis dacă le iei pe rând. Și cea mai utilă veste e că partea la care se uită toți — modelul de limbaj — e aproape niciodată cea mai scumpă.
Un sistem RAG are două bugete complet diferite: unul plătit o singură dată (construcția) și unul care curge lună de lună (operarea). Se confundă des în discuții, dar se comportă opus. Build-ul e dominat de muncă umană. Operarea, de consum de API și infrastructură. Dacă vrei o recapitulare pe ce este și când folosești RAG, pornește de acolo; aici vorbim doar despre bani.
O notă de citit prețurile: serviciile de cloud și API se facturează în dolari, așa că le las în USD. Costurile de construcție le dau în euro, ca buget de proiect — și cu mențiunea că o echipă internă sau un dezvoltator din Europa de Est costă sub estimările agențiilor din SUA, de unde vin cele mai multe cifre publice.

Gândește-le ca pe o mașină. Build-ul e prețul de achiziție: îl plătești o dată, e mare, și depinde de cât de echipată vrei mașina. Operarea e benzina, asigurarea și service-ul: curge constant, e mai mică pe lună, dar nu se oprește niciodată.
Greșeala clasică e să negociezi luni de zile pe prețul de achiziție și să uiți complet de benzină. La RAG, operarea pe doi ani depășește des costul inițial de build — mai ales dacă alegi prost modelul sau infrastructura.
Build-ul se împarte în trei trepte, în funcție de cât de serios e sistemul.
| Treaptă | Ce include | Cost orientativ (build) |
|---|---|---|
| RAG simplu | o singură sursă, vector DB în cloud, chat de bază, fără control de acces granular | €12.000–€22.000 |
| RAG de producție | surse multiple, hybrid search, control de acces pe roluri, integrare helpdesk/Slack, audit log | €35.000–€70.000 |
| RAG enterprise on-prem | self-hosted complet, model local, SSO, conformitate (GDPR, ISO 27001), ingestie incrementală | €75.000–€150.000+ |
Cifrele sunt orientative. Estimările din SUA pe 2026 sunt mai sus — un RAG simplu acolo pleacă de la $15.000–$25.000, unul de producție de la $40.000–$80.000, iar enterprise on-prem trece de $80.000–$150.000. Cu o echipă internă sau cu rate est-europene, aterizezi sub aceste praguri pe aceeași complexitate.
Aici e contraintuitivul. Conectarea unui model de limbaj la o bază de cunoștințe e partea ușoară — câteva zile de lucru. Banii se duc în altă parte.
Curățarea și pregătirea datelor înghite 30–50% din bugetul de proiect. Documentele tale nu vin formatate frumos. Sunt PDF-uri scanate, pagini Confluence inconsistente, tichete vechi cu metadata lipsă. Tot ce intră în sistem trebuie curățat, deduplicat și structurat înainte de vectorizare. Cine a construit un pipeline real pe PDF-uri de producție știe exact de ce.
Restul costului de build se distribuie pe lucruri pe care le uiți la prima estimare: strategia de chunking (cum tai documentele afectează direct calitatea — necesită experimentare, €2.000–€5.000), hybrid search (combini căutarea vectorială cu cea pe cuvinte-cheie, €1.500–€3.000), filtrarea pe metadata (€1.000–€2.500) și iterația pe prompt (15–30 de ore de expert ca să scoți răspunsuri bune). Adaugă stratul de control al accesului și integrările — și ai bugetul real.

Repartiția tipică a efortului la construcția unui RAG de producție. Modelul de limbaj e ultima ta grijă pe buget.
Concluzia practică: dacă cineva îți vinde un RAG și jumătate din discuție e despre ce model folosește, întreabă-l cât alocă pe curățarea datelor și pe integrări. Acolo se câștigă sau se pierde proiectul.
Operarea are patru componente: generarea răspunsului (LLM), vectorizarea (embeddings), baza de date vectorială și hosting-ul. Le luăm pe rând, cu cifre.
Aici e singura pârghie care îți poate înmulți factura cu zece. O interogare RAG nu trimite doar întrebarea: trimite și contextul recuperat — câteva fragmente din baza ta de cunoștințe, plus system prompt și eventual istoricul conversației. În total, ~3.000 de tokeni de intrare și ~250 de tokeni de răspuns per interogare e o estimare realistă.
Cu asta, costul per interogare depinde brutal de model:
| Model | Input ($/1M) | Output ($/1M) | Cost/interogare* | ~10k conversații/lună** |
|---|---|---|---|---|
| GPT-4.1 Mini | $0.40 | $1.60 | ~$0.0016 | ~$80 |
| GPT-5 | $1.25 | $10.00 | ~$0.006 | ~$300 |
| GPT-4.1 | $2.00 | $8.00 | ~$0.008 | ~$400 |
| GPT-5.5 | $5.00 | $30.00 | ~$0.0225 | ~$1.100 |
** ~3.000 tokeni context + ~250 tokeni răspuns. ** ~5 interogări pe conversație.*
De la cel mai ieftin la cel mai scump model, factura sare de ~14 ori pentru exact același trafic. Alegerea modelului e cea mai mare decizie de cost pe care o iei — mai mare decât baza de date, mai mare decât hosting-ul. Iar vestea bună e că pentru majoritatea întrebărilor dintr-un RAG bine construit, un model mic dă răspunsuri la fel de bune ca unul de top, fiindcă greul îl face retrieval-ul, nu modelul.
Embeddings-urile sunt partea ieftină care sperie pe toți degeaba. Vectorizezi corpusul o singură dată la ingestie, apoi vectorizezi doar întrebarea la fiecare interogare.
Prețurile pe 2026: text-embedding-3-small de la OpenAI costă $0.02 per milion de tokeni (1.536 dimensiuni) și e baseline-ul de cost-performanță pentru RAG general. Varianta large urcă la $0.13/milion (3.072 dimensiuni). Mistral Embed e și mai jos, ~$0.01/milion.
Pune cifrele în context: 50.000 de documente înseamnă ~50 de milioane de tokeni, adică ~$1 o singură dată ca să vectorizezi tot. Vectorizarea întrebărilor la 10.000 de interogări pe lună costă câțiva cenți. Embeddings-urile nu sunt o linie de buget — sunt zgomot. Singura excepție: dacă schimbi modelul de embedding, ești forțat să re-vectorizezi tot corpusul, iar reconstrucția indexului devine un eveniment costisitor (vezi mai jos).
Aici ai cea mai mare paletă de opțiuni și cea mai mare șansă să plătești greșit. Iată terenul pe 2026:
| Opțiune | Model de preț | ~Cost lunar (mic–mediu) |
|---|---|---|
| MongoDB Atlas Flex | plafon pay-as-you-go (suportă Vector Search) | $8–$30 |
| MongoDB Atlas M10 | cluster dedicat | ~$58 |
| Pinecone Serverless | read/write units + storage, scale-to-zero | ~$70 la 10M vectori |
| Qdrant (self-hosted pe VPS) | cost fix de server, fără taxă per query | $30–$50 |
| pgvector pe RDS | extensie Postgres | ~$45 |
Cât spațiu ocupă? Un milion de fragmente vectorizate cu un model de 1.536 de dimensiuni înseamnă ~6 GB de date brute, ~9 GB cu overhead-ul de index (HNSW adaugă ~1,5x). Dacă folosești embeddings de 3.072 de dimensiuni, dublezi.
Regula de decizie: la trafic mic și mediu, o opțiune serverless sau cu plafon (Pinecone, Atlas Flex) e mai ieftină și fără bătaie de cap operațională. La volum mare de interogări — undeva peste 60–80 de milioane de query-uri pe lună — un Qdrant sau pgvector self-hosted pe server fix ajunge să coste de câteva ori mai puțin decât echivalentul serverless. Sub acel prag, plătești degeaba pentru ops.
Atenție la costurile ascunse pe care calculatoarele de preț le omit: egress (transferul datelor afară, ~$0.08–$0.09/GB pe AWS), reconstrucția indexului ($12–$40 la 10M de vectori) și backup-ul (~20% din costul cluster-ului la opțiunile dedicate).
Aplicația în sine — API-ul, interfața de chat, orchestrarea — stă pe ~$100–$500 pe lună pentru hosting și baze de date adiacente, în funcție de trafic. Adaugă 5–10 ore pe lună de monitorizare și îmbunătățire: un RAG nu e „build it and forget it", are nevoie de tuning pe prompt și de actualizarea bazei de cunoștințe.
Teoria e clară; hai pe exemple. Trei sisteme reale, trei bugete.
| Scenariu | Corpus | Trafic | Build (one-time) | Operare/lună |
|---|---|---|---|---|
| Asistent intern mic | ~10k documente | ~1k conversații | €12k–€20k | ~$60–$120 |
| Customer support mediu | ~50k documente | ~10k conversații | €35k–€65k | ~$300–$800 |
| Enterprise on-prem | 500k+ documente | 100k+ conversații | €75k–€150k+ | ~$1.500–$6.000 |
Asistentul intern mic răspunde la întrebările echipei pe help center și wiki. O sursă, chat simplu, fără control de acces complicat. Operarea e dominată de câțiva dolari de LLM pe lună (model mic) plus un cluster Flex de $15–$30. Poți chiar porni pe tieruri gratuite cât validezi.
Customer support-ul mediu trage din docs de produs, tichete și KB, cu hybrid search și integrare în helpdesk. Aici factura lunară depinde aproape integral de modelul ales: ~$80 cu un model mic, ~$400 cu unul mediu, peste $1.000 dacă pui modelul de top pe fiecare interogare. Baza de date adaugă $40–$70, hosting-ul și monitorizarea încă $150–$300.
Enterprise on-prem rulează model self-hosted pe GPU pentru suveranitatea datelor. Costul se mută de la API la infrastructură: $300–$500 pe lună per server GPU, vector DB dedicat de $200–$700, plus 20–30% din timpul unui inginer senior pentru operare. Build-ul e mare pentru că include SSO, conformitate și ingestie incrementală — exact lucrurile care nu apar într-un demo.
Înainte să accepți un cost lunar, verifică dacă sunt aplicate astea. Fiecare e bani reali.
Pentru un sistem real, cu surse multiple și control de acces, pleci de la ~€35.000 build plus ~$300–$500 pe lună operare. Pentru un MVP intern pe o singură sursă, scazi mult: build sub €20.000 și câțiva zeci de dolari pe lună.
Doar la volum. Un model open-source pe GPU costă $300–$500/lună plus timp de DevOps. Sub un anumit prag de interogări, API-ul gestionat e mai ieftin și fără ops; peste el, self-hosted câștigă. Calculează pragul pe traficul tău, nu pe presupuneri.
Re-vectorizarea e ieftină ($20–$120 pentru un miliard de tokeni, în funcție de model), iar reconstrucția indexului e $12–$40 la 10M de vectori (până la $120–$400 la 100M). Partea scumpă nu e calculul, ci disrupția de inginerie când schimbi modelul de embedding și ești forțat să refaci tot.
Da, și e abordarea corectă. Pornește pe un tier Flex, un model ieftin și o singură sursă. Urci tier-ul, modelul și baza de date pe măsură ce crește traficul, fără să rescrii sistemul.
Pentru dezvoltare, da: MongoDB M0, Pinecone cu 2 GB, Qdrant cu 1 GB, sau orice opțiune open-source self-hosted. Bune pentru MVP și prototip, dar fără SLA — nu le pune sub trafic de producție.
Modelul de limbaj e costul vizibil, dar rar cel dominant. Banii reali se duc în pregătirea datelor, integrări și mentenanță — exact componentele care nu apar într-un demo strălucitor. Dacă scopezi strâns, pornești de la un singur use-case și măsori înainte să scalezi, un RAG e mult mai accesibil decât sugerează cifrele mari de pe paginile de „enterprise".
Vrei o estimare pe cazul tău concret — corpus, trafic, cerințe de conformitate? Pornește de la serviciile de integrare AI și RAG și spune-ne ce vrei să automatizezi.
RAG conectează modelul la baza ta de cunoștințe ca să răspundă clienților pe surse reale, cu citare. Unde pui sistemul, ce alegi și ce eviți.
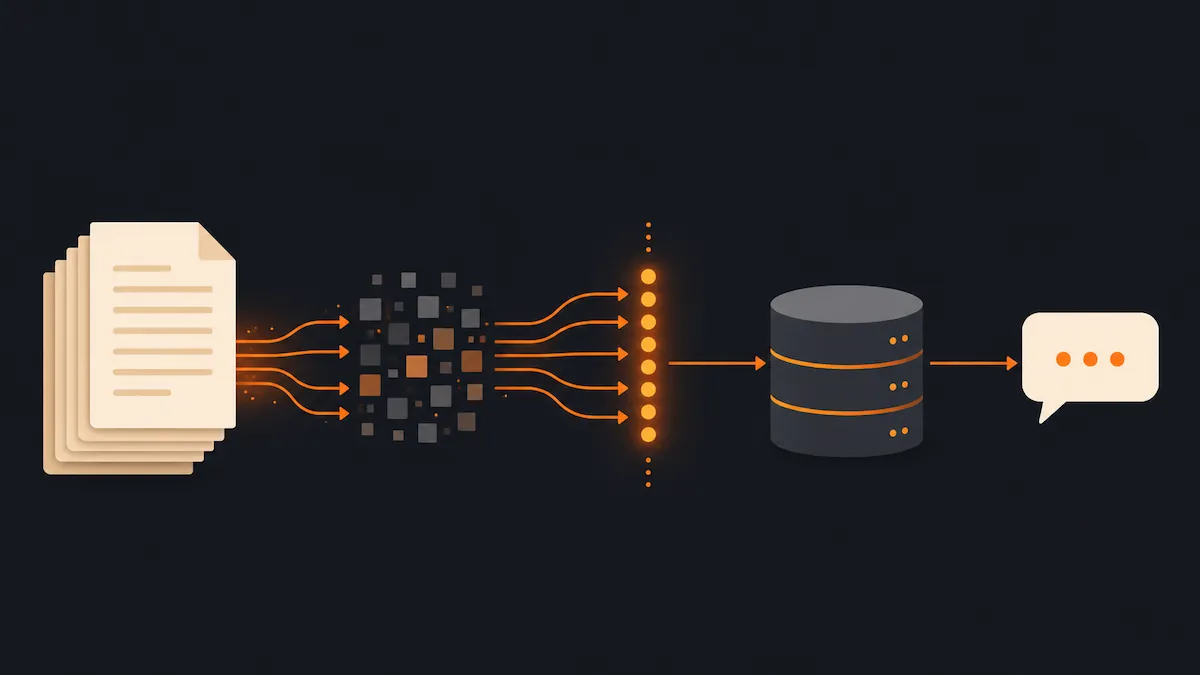
Construiești un sistem RAG complet pe stack-ul tău: Next.js, Vercel AI SDK și MongoDB Atlas. Cod real, pas cu pas, de la ingestion la răspuns.

Compari RAG cu fine-tuning pe 8 criterii. Vezi 3 scenarii cu cost real și decision tree în 4 întrebări pentru a alege arhitectura corectă.
Articole noi despre ERP, AI, agenți și pSEO, direct pe email. Fără spam.